
The AI team at Datactics is building explainability from the ground up and demonstrating the “why and how” behind predictive models for client projects.
Matt Flenley prepared to open his brains to a rapid education session from Dr Fiona Browne and Kaixi Yang.
One of the most hotly debated tech topics of 2020 concerns model interpretability, that is to say, the rationale of how an ML algorithm has made a decision or prediction. Nobody doubts that AI can deliver astonishing advances in capability and corresponding efficiencies in an effort, but as HSBC’s Chief Data Officer Lorraine Waters shared at a recent A-Team event, “is it creepy to do this?” Numerous agendas at conferences are filled with differing rationales for interpretability and explainability of models, whether business-driven, consumer-driven, or regulatory frameworks to enforce good behaviour, but these are typically ethical conversations first rather than technological ones. It’s clear we need to ensure technology is “in the room” on all of these drivers.
We need to be informed and guided by technology to see what tools are already available to help with understanding AI decision-making, how tech can help shed light on ‘black boxes’ just as much as we’re dreaming up possibilities for the use of those black boxes.
As Head of Datactics’ AI team, Dr Fiona Browne has a strong desire for what she calls ‘baked-in explainability’. Her colleague Kaixi Yang explains more about explainable models,
Some algorithms, such as neural networks (deep learning), are complex. Functions are calculated through approximation, from the network’s structure it is unclear how this approximation is determined. We need to understand the rationale behind the model’s prediction so that we can decide when or even whether to trust the model’s prediction, turning black boxes into glass boxes within data science.
The team puts their ‘explain first‘ approach to a specific client project to build explainable Artificial Intelligence (XAI) from the ground up, using explainability metrics including LIME – a local, interpretable, model-agnostic way of explaining individual predictions.
“Model-agnostic explanations are important because they can be applied to a wide range of ML classifiers, such as neural networks, random forests, or support vector machines” continued Ms Yang, who has recently joined Datactics after completing an MSc in Data Analytics with Queen’s University in Belfast. “They help to explain the predictions of any machine learning classifier and evaluate its usefulness in various tasks related to trust”.
For the work the team has been conducting, these range of explainability measures provides them with the ability to choose the most appropriate Machine Learning model and AI systems, not just the one that makes the most accurate predictions based on evaluation scores. This has had a significant impact on their work on Entity Resolution for Know Your Customer (KYC) processes, a classic problem of large, messy datasets that are hard to match, with painful penalties if it goes wrong for human users. The project, which is detailed in a recent webinar hosted with the Enterprise Data Management Council, matched entities from the Refinitiv PermID and Global LEI Foundation’s datasets and relied on human validation of rule-based matches to train a machine learning algorithm.
Dr Browne again: “We applied different explainability metrics to three different classifiers that could predict whether a legal entity would match or not. We trained, validated and tested the models using an entity resolution dataset. For this analysis we selected two ‘black-box”’classifiers, and one interpretable classifier to illustrate how the explainability metrics were entirely agnostic and applicable regardless of the classifier that was chosen.”
The results are shown here:
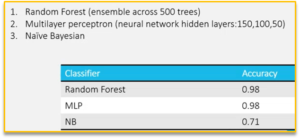
“In a regular ML conversation, these results indicate two reliably accurate models that could be deployed in production,” continued Dr Browne, “but in an XAI world we want to shed light on how appropriate those models are.”
By applying, for example, LIME to a random instance in the dataset, the team can uncover the rationale behind the predictions made. Datactics’ FlowDesigner rules studio automatically labelled this record as “not a match” through its configurable fuzzy matching engines.
Dr Browne continued, “explainability methods build an interpretable classifier based on similar instances to the selected instance from the different classifiers and summarises the features which are driving this prediction. It selects those instances that are quite close to the predicted instance, depending on the model that’s been built, and uses those predictions from the black-box model to build a glass-box model, where you can then describe what’s happening.
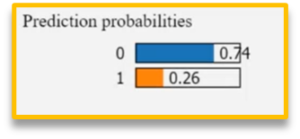
In this case, for the Random Forest model (fig.), the label has been correctly predicted as 0 (not a match) and LIME exposes the features driving this decision. The prediction is supported by two key features but not a feature based on entity name which we know is important”
Using LIME on the multilayer perceptron model (fig.), which had the same accuracy as Random Forest, it correctly predicted the “0” label of “not a match” but with a lower support score. It has been supported by slightly different features compared to the random forest model.

The Naïve Bayesian model was different altogether. “It fully predicted the correct label of zero with a prediction confidence of one, the highest confidence possible,” said Dr Browne, “however it’s made this prediction supported by only one feature, a match on the entity country, disregarding all other features. This would lead you to doubt whether it’s reliable as a prediction model.”
This has significant implications in something as riddled with differences in data fields as KYC data. People and businesses move, directors and beneficial owners resign, and new ones are appointed, and that’s without considering ‘bad actors’ who are trying to hoodwink Anti-Money Laundering (AML) systems.

The process of ‘phoenixing’, where a new entity rises from the ashes of a failed one, intentionally dodging the liabilities of the previous incarnation, frequently relies on truncations or mis-spellings of director’s names to avoid linking the new entity with the previous one.
Any ML model being used on such a dataset would need to have this explainability baked-in to understand the reliability of predictions that the data is informing.
Using one explainability metric only is not good practice. Dr Browne explains Datactics’ approach: “Just as in classifiers, there’s no real best evaluation approach or explainer to pick; the best way is to choose a number of different models and metrics to try to describe what’s happening .There are always pros and cons, ranging from the scope of the explainer to stability of the code to complexity of the model and how and when it’s configured.”
These technological disciplines, to test, evaluate and try to understand a problem are a crucial part of the entire conversation that businesses are having at an ethical or “risk appetite” level.
Click here for more from Datactics, or find us on Linkedin, Twitter or Facebook for the latest news.