Augment Your Data Quality
Augmented Data Quality from Datactics delivers trust in the data that matters to your business.
Seamlessly combine data quality with AI and automation to save time, reduce risk and increase business revenue.

Empower business users to create value and deliver efficiencies through better quality data.
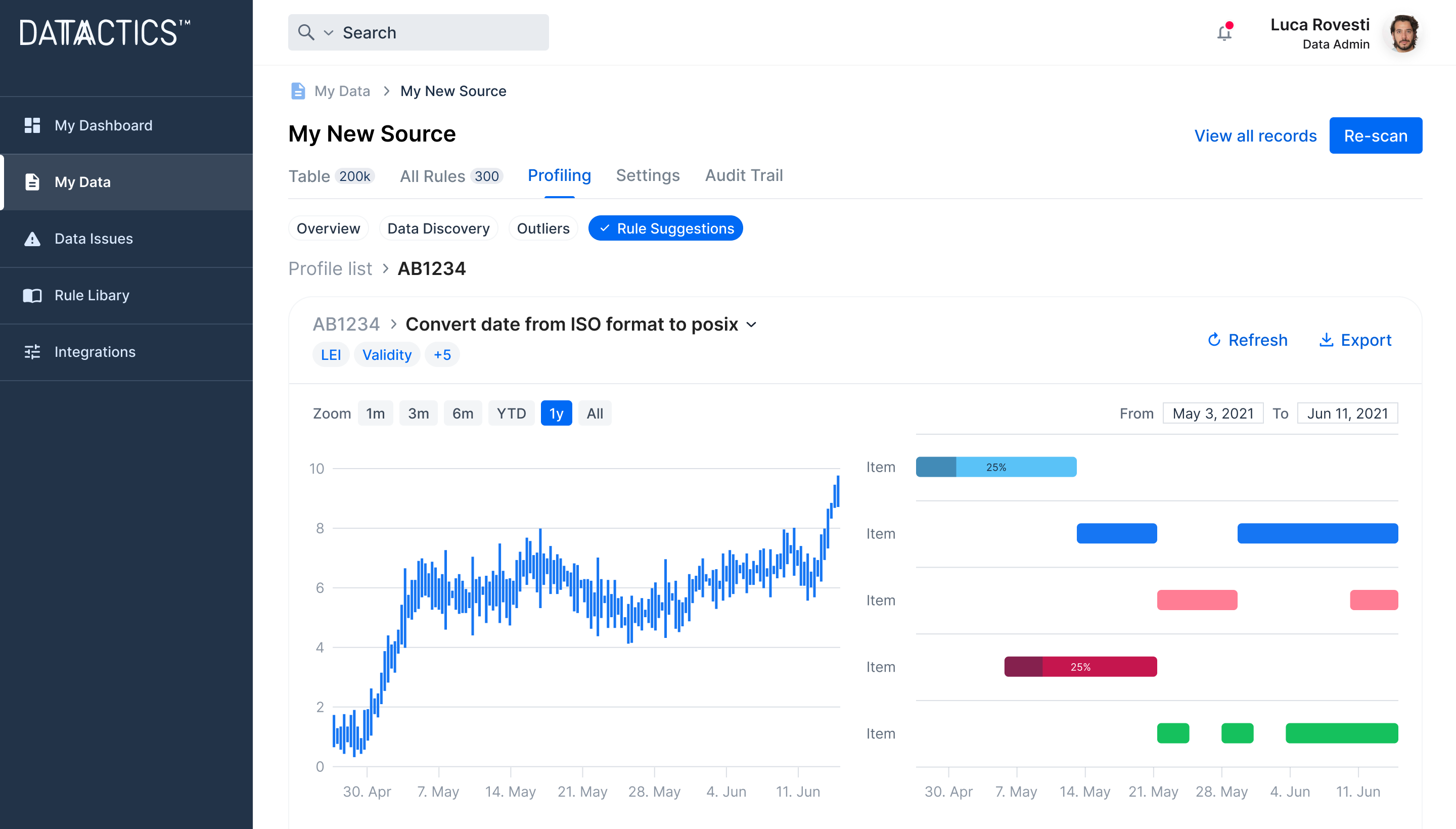
Simply pick your data source, connect and get started. The platform provides comprehensive data profiling and automated rule suggestion to reduce human effort and time taken in complex rule building.
Go beyond just reporting bad data: find and fix it with a full audit trail, using AI-powered recommendations.
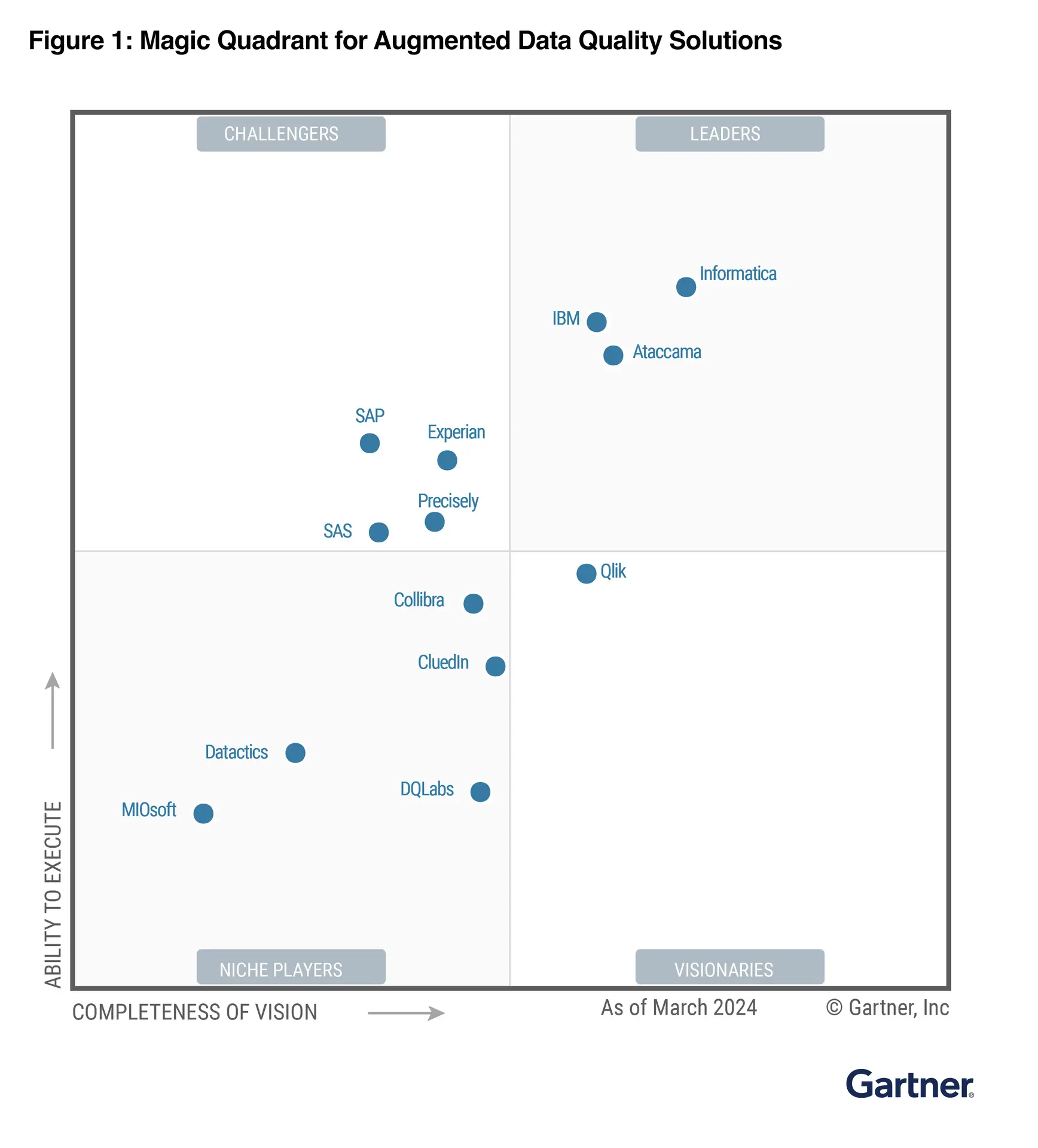
Datactics is delighted to be recognised in the March 2024 Gartner Magic Quadrant for Augmented Data Quality Solutions. Click below to gain complimentary access to this report.
End-to-end continuous data quality delivering business value
Demonstrate value faster with AI-suggested data quality rules
Get a head start on your data management strategy with 70% of reusable data quality rules automatically suggested. Reduce your reliance on IT resources and coders to build and deploy data quality rules, reducing costly bottlenecks.
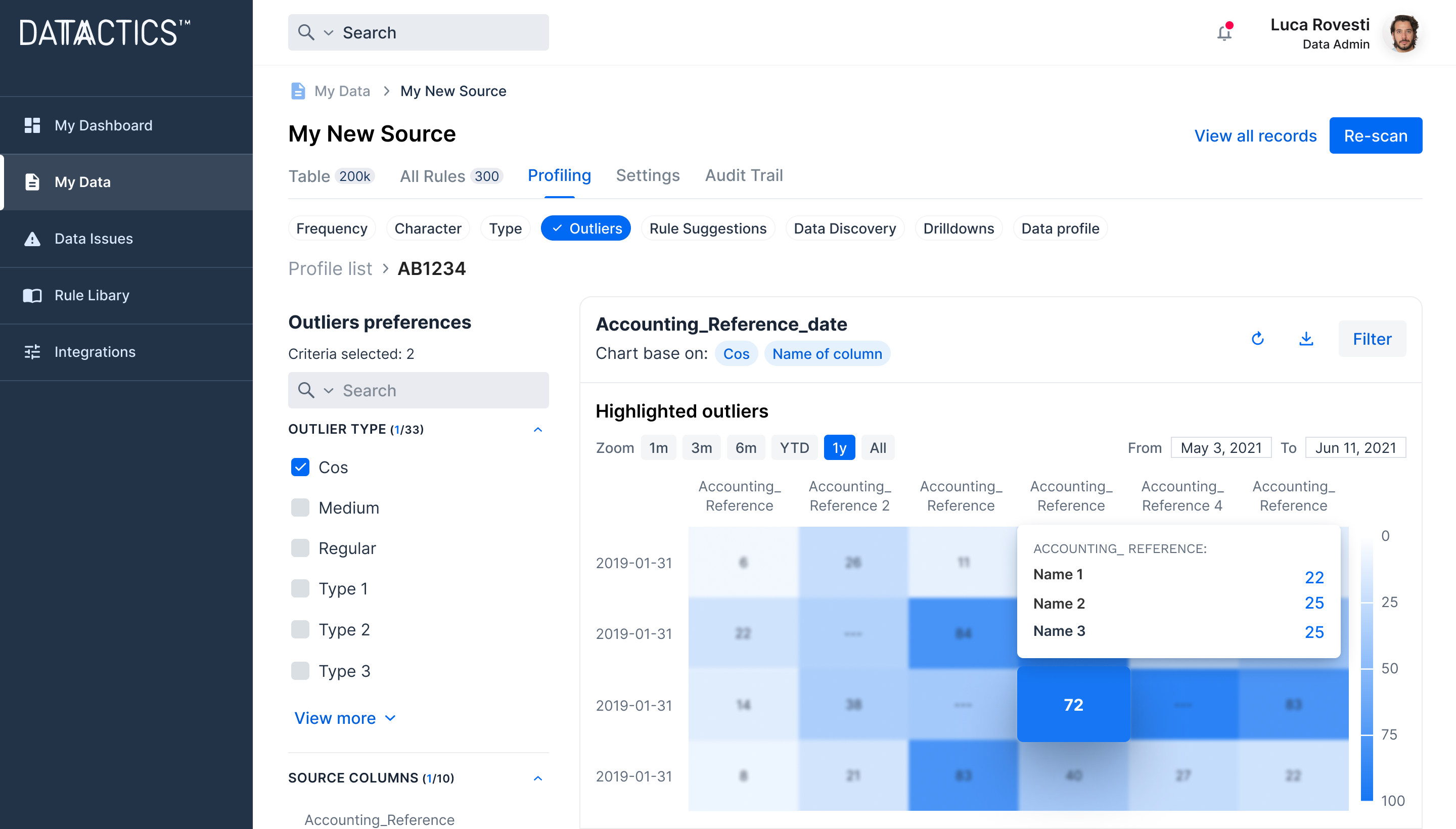
Remove the mystery of why data quality errors occur
Dig deep into the causes of poor data quality, predict future data breaks and conduct true root cause analysis. Save time spent manually trawling through broken data records to help prevent future breaks from occurring.
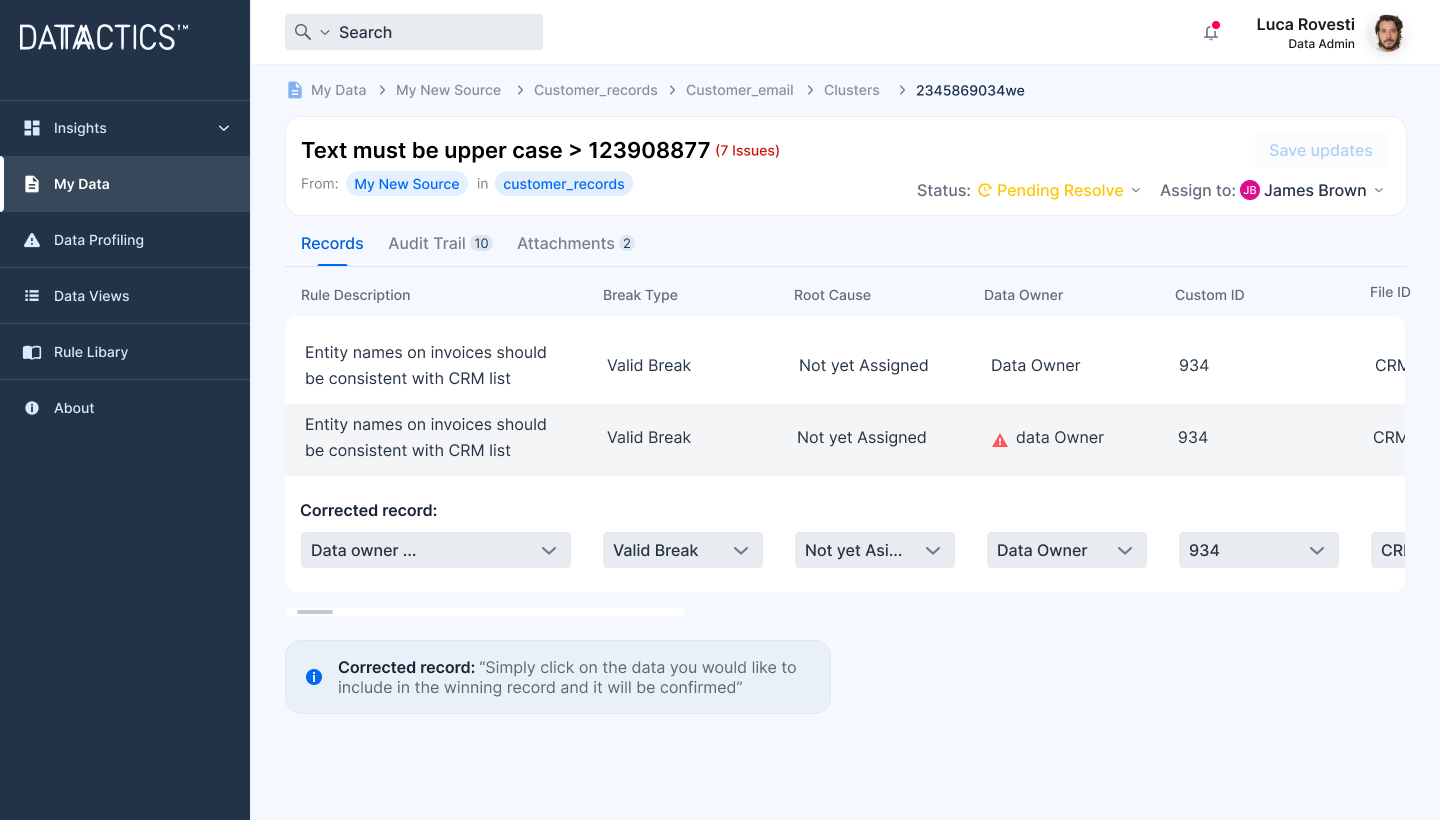
Fix your broken data, don't just observe it
Move beyond data observability to fix the data breaks being measured and reported. Make your insights make a difference to the quality of data your business relies upon.
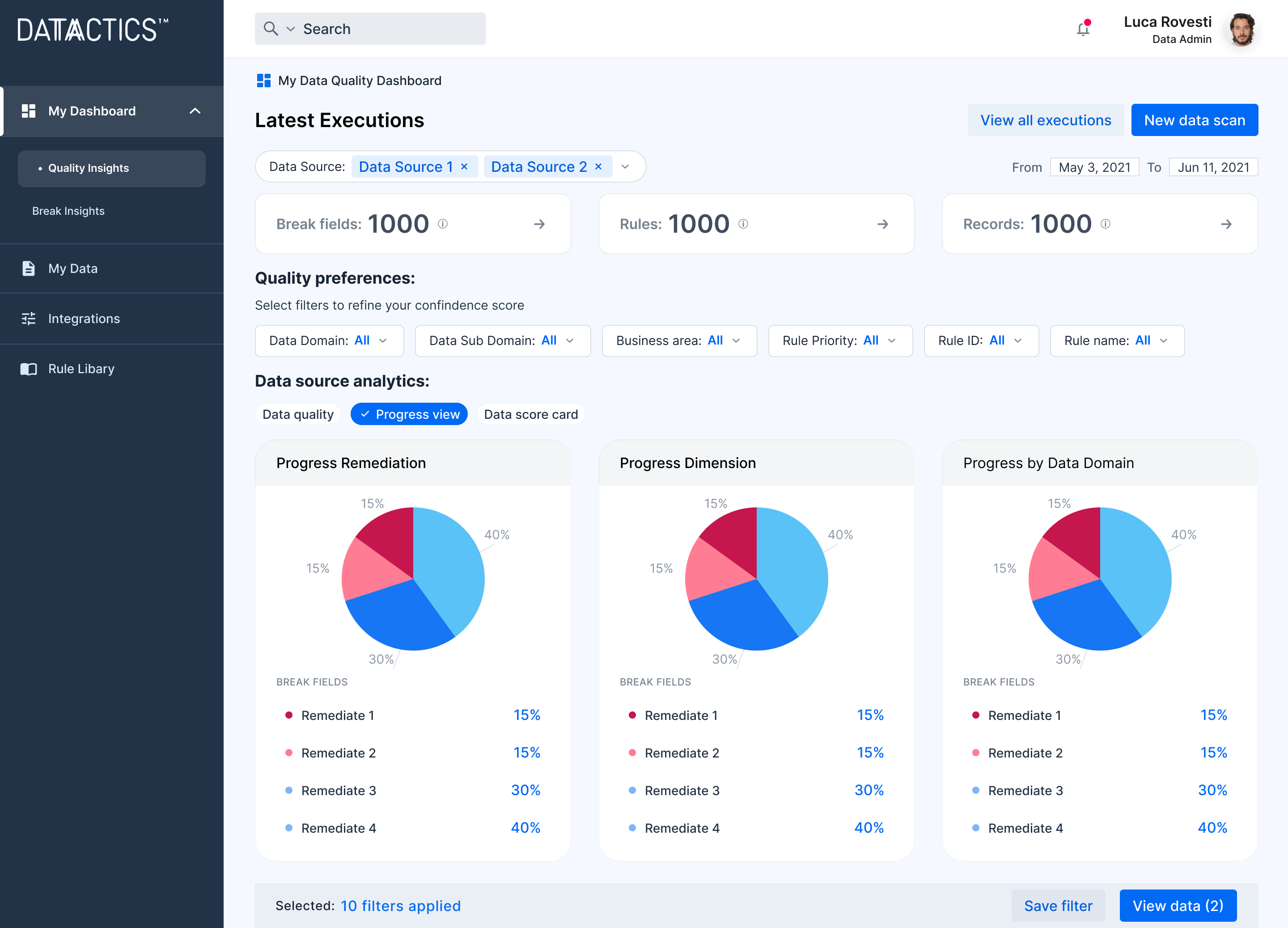
Gain buy-in with easily relatable data stories
Easily monitor the health of the data that matters to you and your business in clear, rich dashboards. Drive better decisions and discover new avenues to revenue through better data health.
We make it easy to work together on your data management journey
Our data engineers, developers and data scientists work at the cutting edge of data management technology to save you precious time and accelerate your data initiatives. Most of our customers choose to start with a Proof of Concept, rapidly demonstrating the value of better data in a real-world use of Datactics technology.
Proof of concept: a fast way to get results

We work with you to define the scope, timeframe and budget. We’re flexible about how you want to achieve your aims and have many satisfied blue-chip clients who can speak for our capabilities. We work with all your stakeholders to help get up and running as soon as you’re ready.

Specifying a subset, or system, is a rapid way of communicating the criticality of data to your organisation. You’ll get a fully-deployable version of our software to demonstrate the value to your business. We’ve a proven track record of working in tight timeframes to get you up and running quickly.

We know that frustration with poor data can seem like a never-ending problem. Our Augmented Data Quality solution delivers measurable, trackable improvement in underlying data quality in metrics that matter to you: reduced costs, reduced risk and increased profitability.

Designed for data people
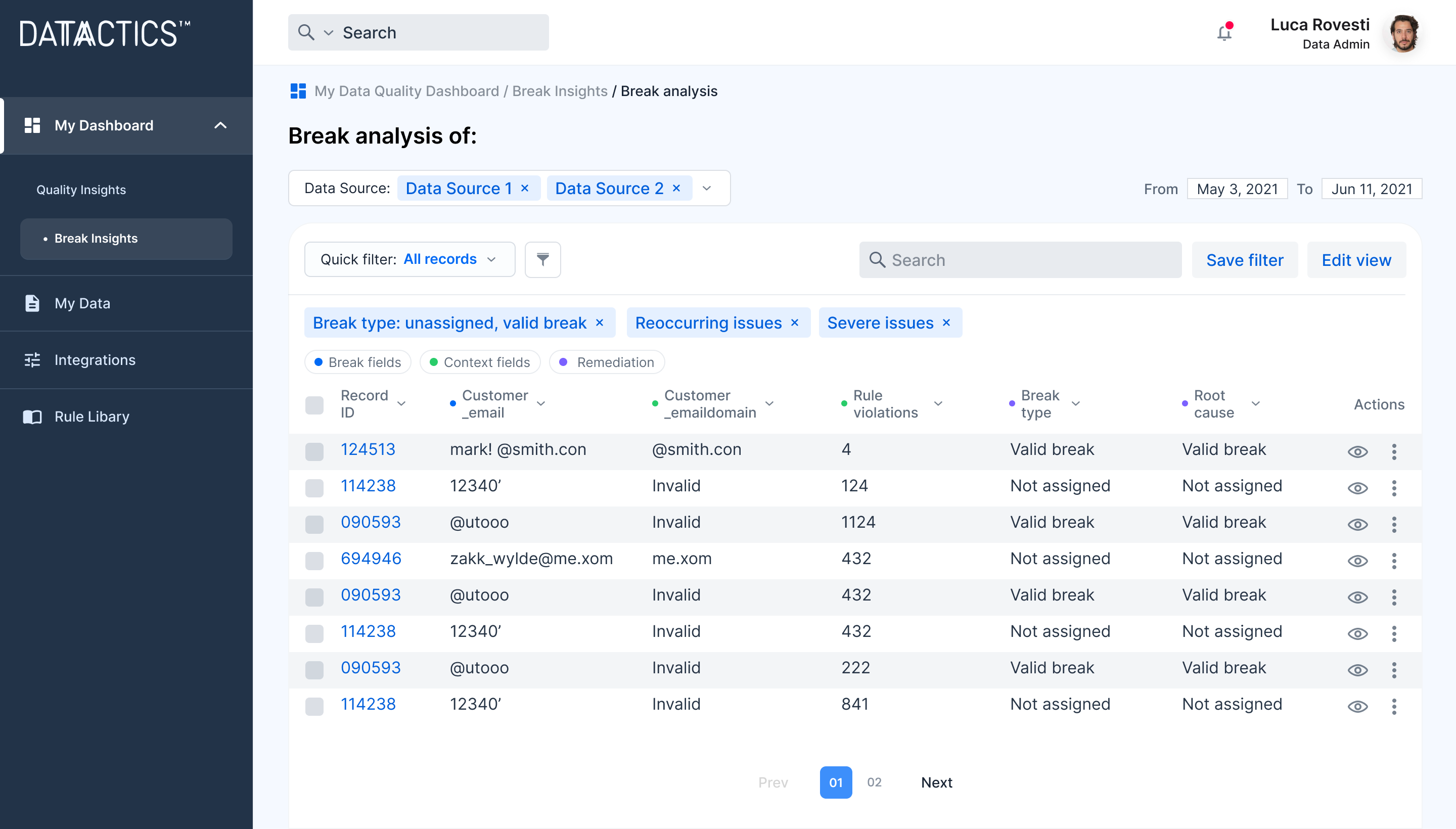
For Business Users
Augmented Data Quality has been perfectly designed for data consumers and business users.
- Gain real-time visibility into your data quality
- Interact with a user-friendly, no-code dashboard
- Easily fix, repair and remediate broken data
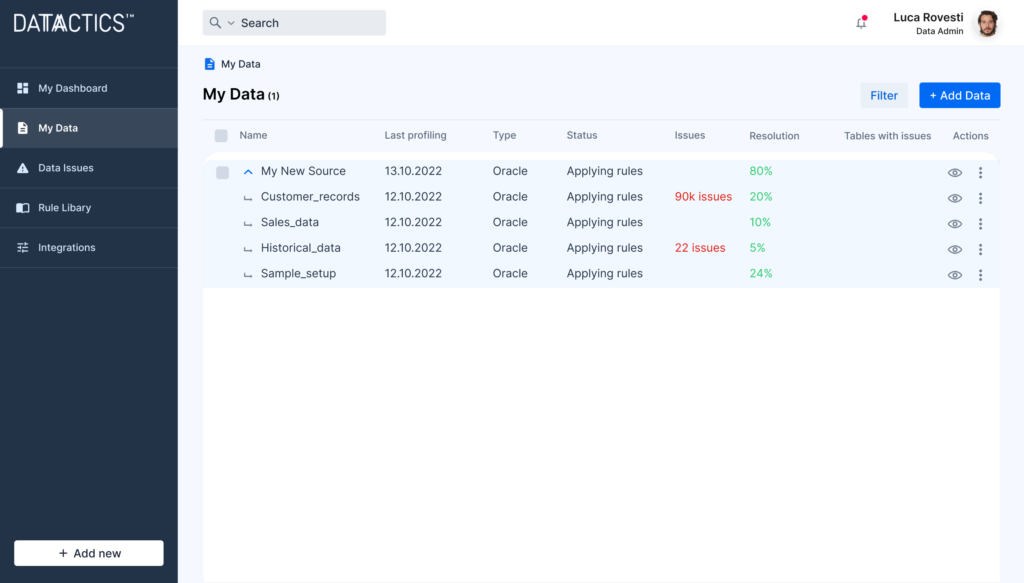
For Data Quality Admins
Systems and database administrators, and those responsible for infrastructure will find Augmented Data Quality easy to implement and and maintain.
- Connecting to databases and data lakes is straightforward and understandable
- Easy to navigate platform has built-in prompts and explainers to support rule building
- Rule creation and definition are performed in a single step, on a single screen
- Easily automate and schedule executions of data quality workflows
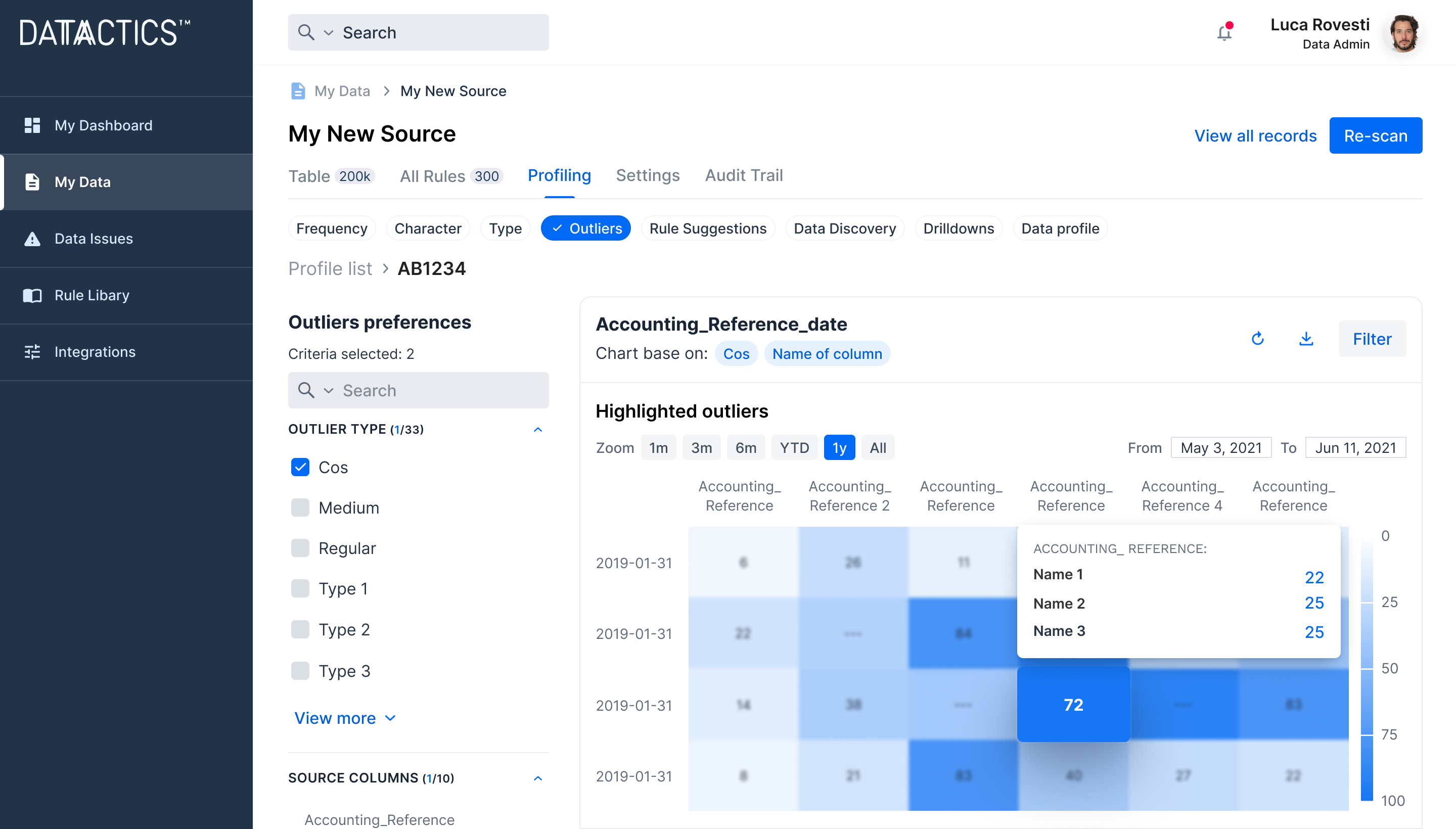
For Data Engineers
Data Engineers will love the clean user interface and AI-driven functionality.
- Data-driven rule creation using ML Insights Hub with enriched insights for smarter rule creation
- Keep track of results and gain insights into future trends within your data.
- Intelligent Data Quality Rule Suggestion with an NLP model to reduce manual effort of building rules
Pre-built integrations across the data stack
Cloud Data Storage
Ships with pre-built connection to Snowflake as a source database.

Data Lakehouse
Pre-built connectivty to Databricks as a source database.

Amazon Web Services
Runs in public or private cloud instances tailored to customer need.
Azure Cloud Services
Runs in private and public cloud instances tailored to customer need.

Data Catalog
Two-way integration to leading enterprise data catalog and governance solution.
Data Lineage
Two-way integration with Solidatus to visualise data ‘at-rest’ and ‘in-motion.’
Built on a proven data quality platform
Augmented Data Quality delivers automation of core data quality processes, augmented by machine learning, underpinned by the core Datactics data quality platform.
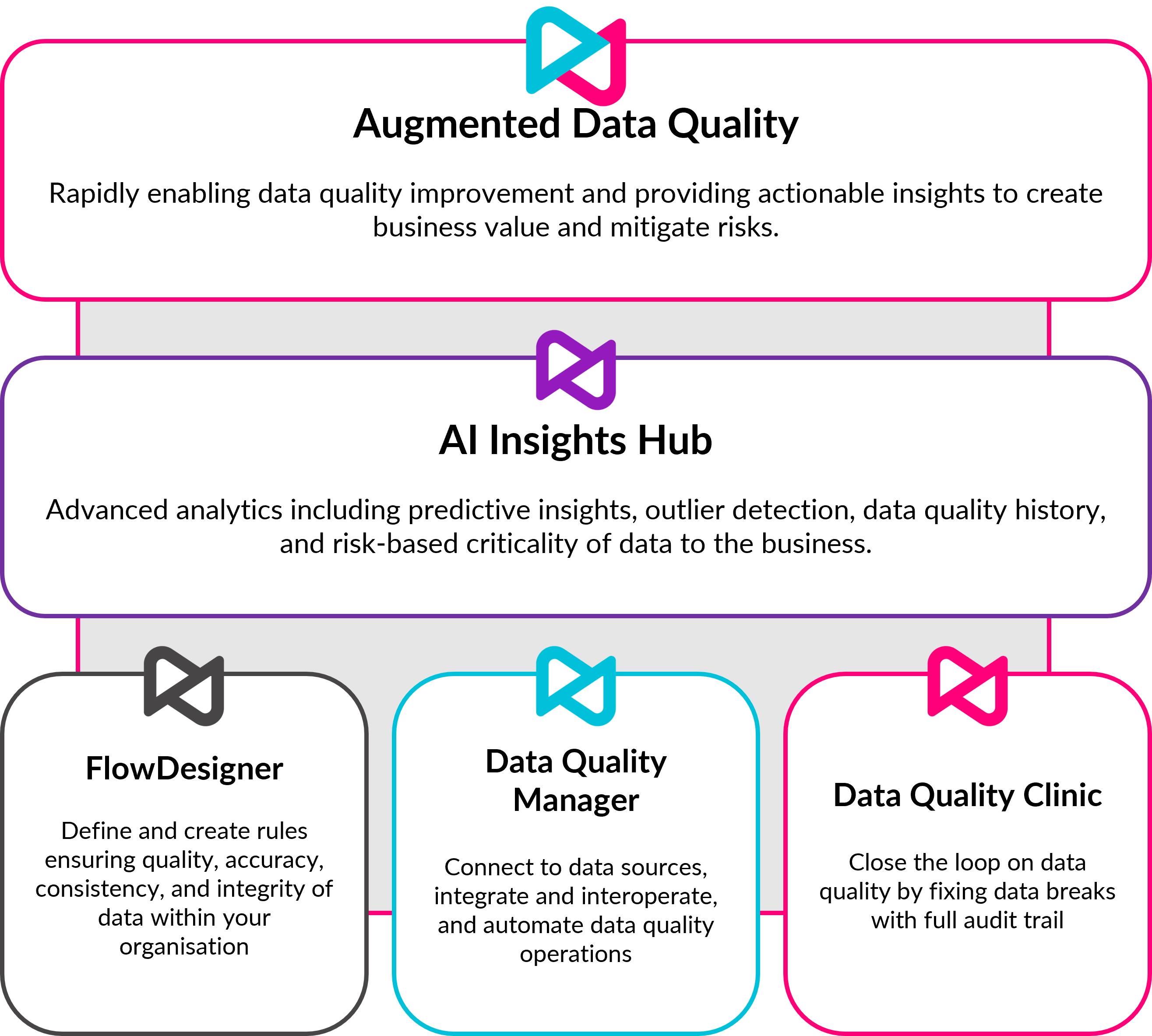
Complete, end-to-end Data Quality
Augmented Data Quality helps deliver fully integrated data quality operations into lines of business.
It provides:
AI-augmented processes to locate and surface data quality errors that are critical to the business
AI-augmented processes to repair bad data, integrating with business workflows and conducting root cause analysis
Connectivity with the Modern Data Stack, including storage, lineage, catalog, MDM, operating natively in cloud.
Datactics Software Components

FlowDesigner
Highly configurable rules studio
Define and create rules to ensure the quality, accuracy, consistency and integrity of data within your organisation.
FlowDesigner empowers data stewards to create a vast array of data quality and preparation rules, including data quality analysis, re-engineering, and rapid data matching at scale.
With FlowDesigner, you can analyse, profile, sort and validate your data. The studio enables re-engineering through cleansing, extraction and splitting the data.
It features powerful matching capabilities, including exact matching, tight and loose fuzzy matching.
- Intuitive design means no coding or programming required
- Built-in, out-of-the-box logic saves time in getting started
- Repeatable, reusable rule logic to accelerate data quality processes

Data Quality Manager
Flexible integration, automation and connectivity tool
Schedule and automate entire data quality processes with connectivty to any data source.
Workflows can be customized to meet specific business needs, ensuring flexibility and adaptability. Importantly, users can build personalised solutions without the need for coding experience, empowering them to customize the software according to their unique requirements.
Data Quality Manager acts as a connectivity hub, facilitating data exchange, interoperability, and seamless connectivity between other Datactics platforms.
It extracts data from the selected sources, facilitating data ingestion and pre-processing; and executes data quality rules and workflows, ensuring that data is validated, cleansed, and enhanced.
- Connects to any data source via API
- Data agnostic software capable of working with any data type
- In-built Rule Dictionary - define your DQ rules here
- Rule weighting - determine how critical a rule is to your specific business requirements
- Dashboarding - identify, understand & monitor your DQ issues, discover patterns and trends over time.

Data Quality Clinic
Data remediation environment
Easily fix broken data with full audit trail.
Data Quality Clinic is our data remediation tool, which acts as a quarantine environment for records that have failed any DQ checks. Accessible from your web browser, broken records are presented alongside contextual data to assist users in their data remediation decisions.
Data Quality Clinic works by making data quality breaks available through your web browser (Chrome or Firefox). It presents the potentially broken data, along with contextual data, that assists users in making a decision about this data.
With Data Quality Clinic, users can remediate broken records; approve or reject suggested amendments; and investigate and amend data breaks. Underlying processes detect any changes made to the record and can push updates automatically at the source.
- Full audit trail of the movement of records throughout the system, including what has been changed and by whom
- Ticket system integration with ServiceNow and Jira, to aid in existing remediation workflows and processes
- Maker-checker workflows and audit trails to manage datsource amendments
- Break type and root cause analysis for proactive data quality
- Bulk remediation for fixing recurring issues across multiple records

Insights Hub
AI-powered data quality insights
Keep track of results and gain insights into future trends within your data.
Improve risk management by measuring the cost of data quality to the business and the impact of data quality management processes, through a rich dashboard driven by analysis and human in the loop machine learning.
- Centralised hub for insights generated from data quality projects
- Rich data quality metrics featuring overview of data quality, including changes to DQ score over time and the number of breaks segmented by data domains, subdomains, and business areas.
- Visualise progress of data remediation efforts, providing a clear picture of resolved and unresolved breaks.
- Advanced analytics through predictive insights, using historical results, the ML model makes predictions on future data breaks, enabling data stewards to take preventative action
- Criticality Insights: The platform provides information on the likelihood of critical data breaks occurring, allowing businesses to prioritise their efforts and focus on high-impact issues.
Accelerate your data strategy with Datactics
We have class-leading professional services designed around our customers and their data management strategies.

Turbocharge your data strategy with support from Datactics Catalyst
With Datactics Catalyst, implement your data management strategy rapidly and efficiently with our services and consulting capabilities. Augment your data teams with certified practitioners aligned with your business goals to quickly deliver value and results.

Create something new built on our technology with Datactics Labs
Through Datactics Labs, leverage our shared R&D approach to create customer-shaped data quality and matching solutions that fit your business model. Develop unique platforms for data management with our flexible technology and equally flexible pricing.
Latest Research
Read our carefully-curated selection of industry thought leadership and technical research conducted by our award-winning technologists.
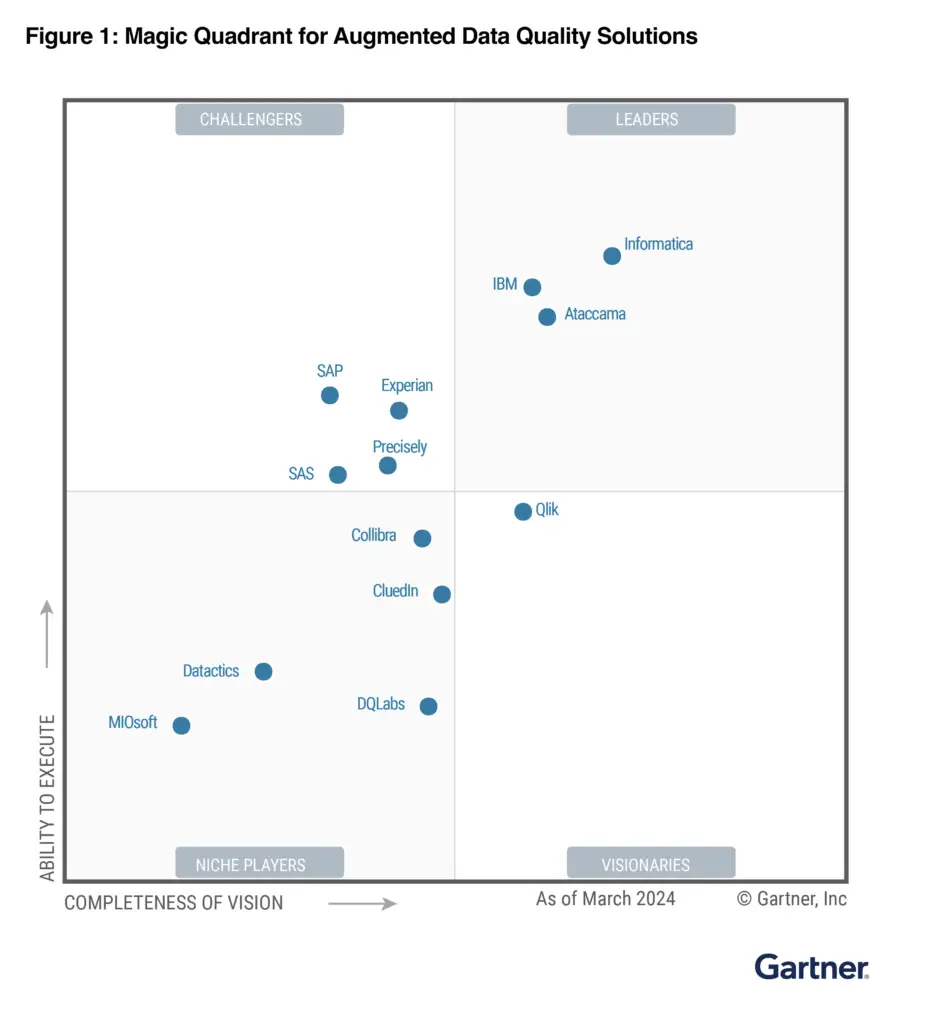
2024 Gartner® Magic Quadrant™ for Augmented Data Quality Solutions
Magic Quadrant for Augmented Data Quality Solutions DOWNLOAD Datactics is named a

ESG Whitepaper – Data & Analytics In Sustainable Finance
Bridging The Gap: Data & Analytics In Sustainable Finance – ESG Whitepaper

Self Service Data Quality Whitepaper
Go beyond simple data prep with AI-augmented self-service data quality from Datactics.
Contact Us
To speak to us about your next step on your data management journey, please get in touch.
The Datactics Team
1 Lanyon Quay, Belfast, BT1 3LG
+ 44 2890 233900